



















Blogs

How to determine critical success factors for customer success using BI tool?
In today's dynamic business landscape, customer success is paramount. But how can organizations ensure they're delivering what their customers truly value? Enter Business Intelligence (BI) tools, the modern-day compass guiding businesses toward understanding and meeting customer needs. Let's explore how BI tool can help determine critical success factors for customer success.

How to know Purchase behavior on your data using BI tool?
In the dynamic landscape of modern business, understanding customer purchase behavior is paramount to success. Every interaction a customer has with your brand leaves a digital footprint, and leveraging this data can provide invaluable insights into their preferences, tendencies, and buying habits.
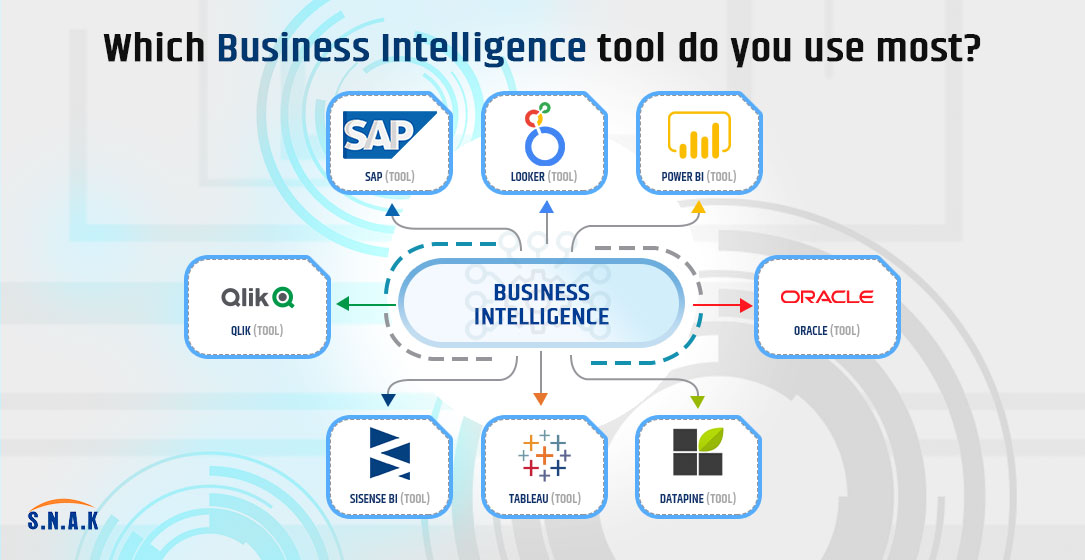
Which Business Intelligence tool do you use most?
Business intelligence tools collect, process, and analyse large amounts of structured
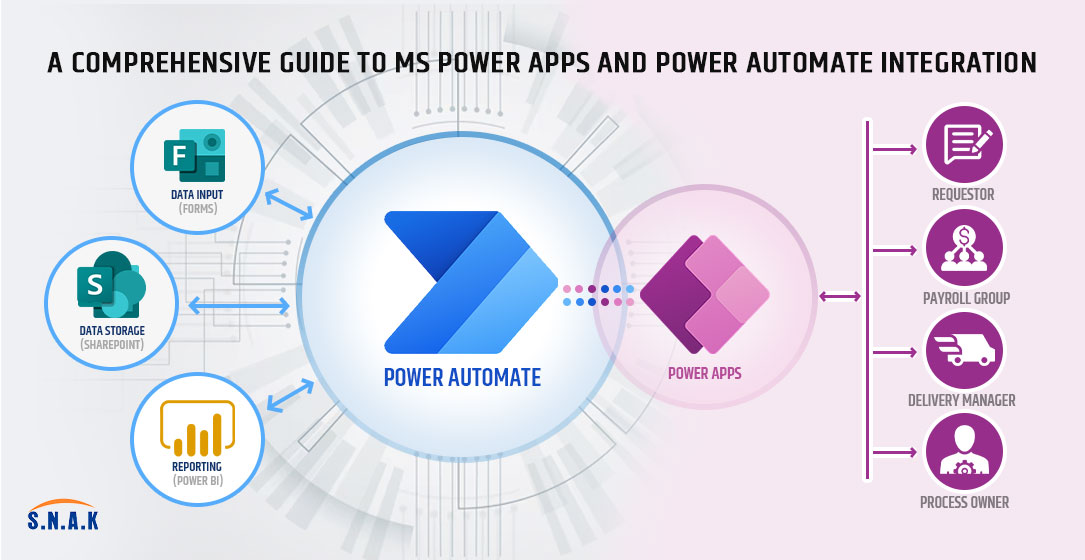
A Comprehensive Guide to MS Power Apps and Power Automate Integration
In the dynamic landscape of digital transformation, Microsoft's Power Platform has
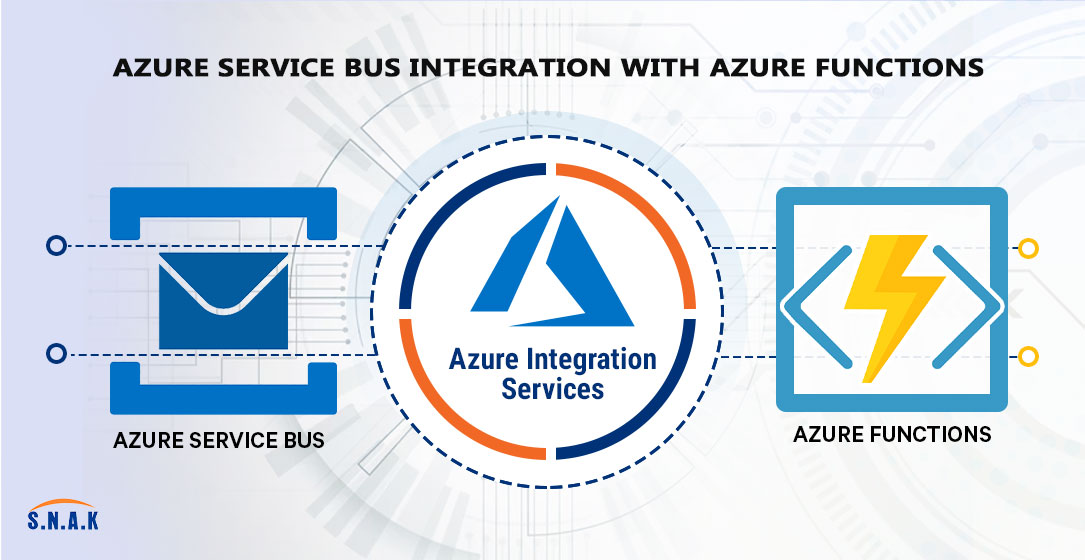
A Deep Dive into Azure Service Bus Integration with Azure Functions
This blog aims to explore the integration between Azure Service Bus and Azure Functions
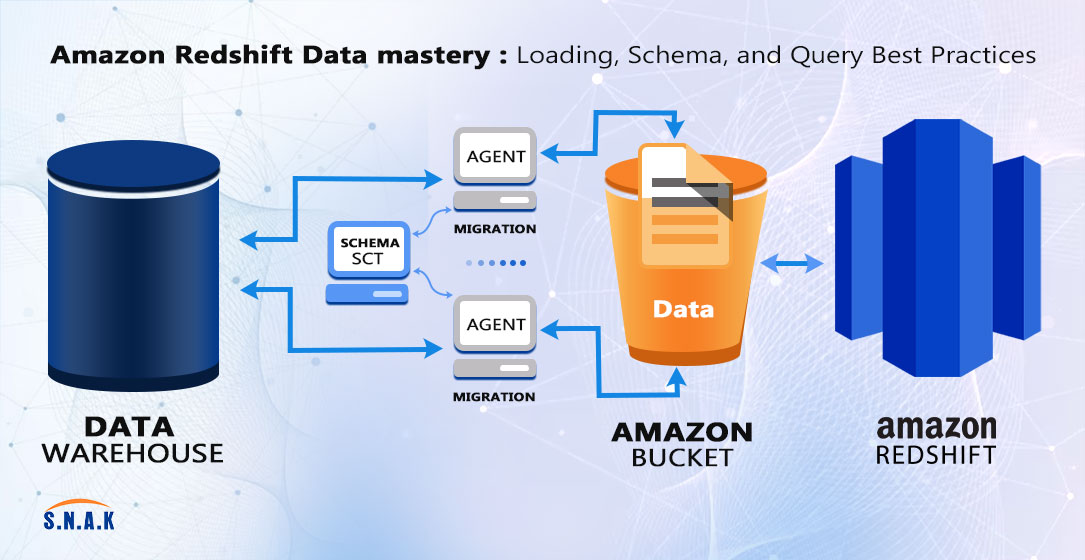
Amazon Redshift Data mastery: Loading, Schema, and Query Best Practices
This blog serves as your guide to navigating the intricate landscape of Redshift, focusing on
Casestudies

Online Harvest Trading in Between Sellers and Buyers
We worked with a start-up company in India that buys and sells crops online through an auction process involving buyers (traders or commission agents), farmers, and shopkeepers.

OCR Based Document Management System
A subsidiary of one of Japan's largest automotive manufacturers, our customer is the largest manufacturer in India of 2-Wheeler vehicles.

MS SharePoint Online Portal and SAP Integration
Our client is India's largest Electrical Manufacturer who operates with a philosophy to carve out a niche in the global fan industry.
Infographics

The BigData that can take your business to the next level

Why are Data lakes of the futute of Big Data?

One Stop Solution for Vehicle Service Care
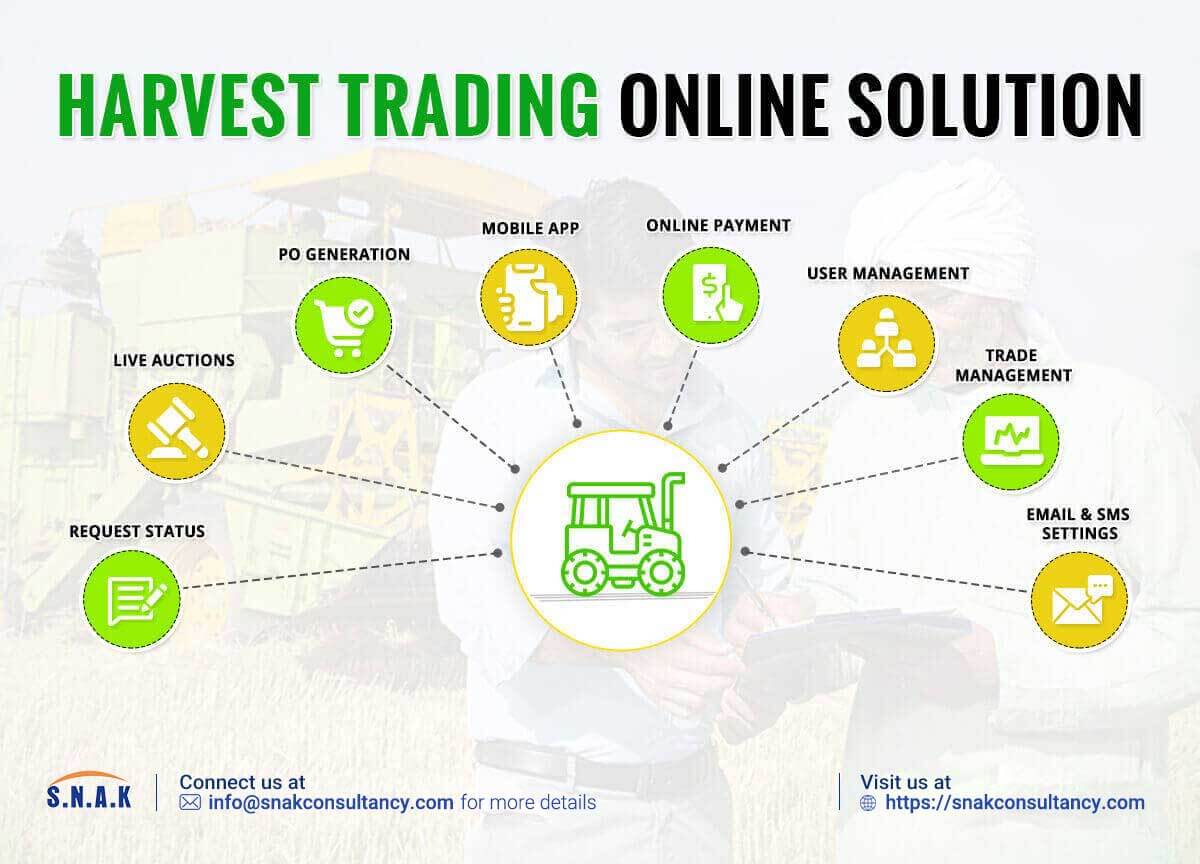
Harvest Trading Online Solution

Transform your technology stack with SNAK


















 Very proactive team with you. They are always willing to accommodate the changes suggested and came out with innovative solutions for many of our requirements.
Very proactive team with you. They are always willing to accommodate the changes suggested and came out with innovative solutions for many of our requirements. 


")